
This blog will guide
1 - How to install Zookeeper on Linux/Mac.
2 - How to install Apache Kafka.
3 - Commands to produce and consume message on Kafka.
Installation of ZooKeeper
- Download latest zoopkeeper from http://zookeeper.apache.org/releases.html.
- Create opt/sotware folder in user directory, It can be any directory. I have extracted zookeeper in /Users/ketangote/opt/zookeeper.
- cd /Users/ketangote/opt/zookeeper/conf
- cp zoo_sample.cfg zoo.cfg
- Open zoo.cfg using nano or vi and update data folder location: dataDir=/Users/ketangote/opt/zookeeper/data
- Start zookeeper commands: sh zkServer.sh start

- Once zookeeper is started, use below command for verification.
telnet localhost 2181
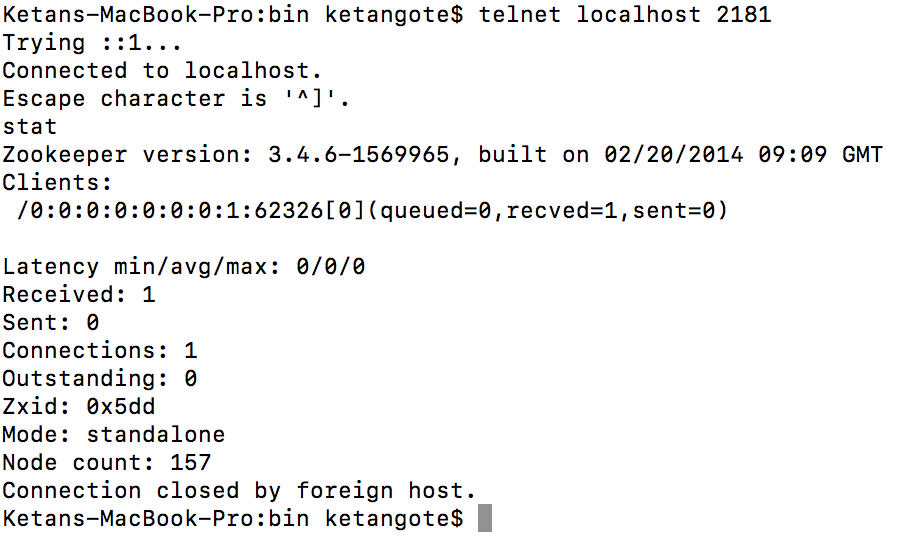
- Stop ZoopKeeper server : shZKServer.sh stop
Installation Of KAFKA
- Download latest Kafka https://www.apache.org/dyn/closer.cgi?path=/kafka/0.10.1.0/kafka_2.11-0.10.1.0.tgz
- Extract folder in /opt folder.It can be any directory.
- Edit config/server.properties as below listeners=PLAINTEXT://:9099 broker.id=1
- Start serversh bin/kafka-server-start.sh config/server.properties
- Stop server sh bin/kafka-server-stop.sh config/server.properties
Commands to Produce and Consume message on Kafka
- Produce a message using below command sh bin/kafka-console-producer.sh --broker-list localhost:9099 --topic topic..... Type some messages
- Consume a message using below command sh bin/kafka-console-consumer.sh --bootstrap-server localhost:9099 --topic ouput --from-beginningThis will display all message which are produce.

Comments
Post a Comment